












DiscoverText
O DiscoverText é um software baseado em nuvem com soluções colaborativas para análise de textos.
Análise de texto colaborativa para aprendizagem humana e de máquina.
Oferecemos dezenas de recursos multilíngues, mineração de texto, ciência de dados, anotação humana e aprendizado de máquina. O DiscoverText oferece uma variedade de ferramentas de software baseadas em nuvem, de simples a avançadas, permitindo que os usuários avaliem com rapidez e precisão grandes quantidades de dados de texto. Nossos clientes classificam textos livres não estruturados comuns em pesquisas de mercado, bem como metadados associados, também encontrados em plataformas de feedback de clientes, CRMs, chats, e-mail, RH em grande escala ou outras respostas abertas em pesquisas, comentários públicos para agências governamentais , Twitter, Feeds RSS e outras formas de dados de texto.
Fabricante: Texifter LLC
Descrição detalhada do produto

SOLICITE SEU ORÇAMENTO
DiscoverText é uma pequena empresa aprovada pelo GSA até 2024 para 54154S e 54151ECOM. Leia mais de 100 comentários autenticados de Capterra para descobrir por que somos classificados em primeiro lugar para análise preditiva, texto, metadados e suporte de análise de rede social, com a confiança de centenas de grupos de pesquisa acadêmica. Os acadêmicos têm acesso e treinamento gratuitos até o final de 2021 .
- Colete, limpe e analise dados de texto.
Dados de texto não estruturados são confusos.
Os cientistas de dados que trabalham com análise de texto sabem que a limpeza de dados pode ser demorada. Os usuários do DiscoverText criam classificadores de máquina personalizados reutilizáveis ou “peneiradores” para encontrar os itens mais (ou menos) relevantes antes de usar outros classificadores para classificar itens em tópico, sentimento e outras categorias. O DiscoverText combina métodos híbridos de ciência de dados (medição, adjudicação, iteração, replicação) junto com ferramentas de análise de texto de descoberta eletrônica estabelecidas, para encurtar um processo que costumava durar semanas ou meses quando as palavras eram classificadas em planilhas . Nossos crivos de aprendizado de máquina são criados em horas ou apenas alguns minutos usando crowdsourcing. Oferecemos uma API e suportamos integrações técnicas com Twitter e SurveyMonkey.Os acadêmicos confiam no DiscoverText para ajudá-los a fazer pesquisas científicas melhores e mais transparentes, resultando em publicações acadêmicas . As equipes jurídicas usam nosso recurso de edição de documentos para remover nomes, metadados, endereços de e-mail e outras informações confidenciais para produzir coleções PDF com carimbo de Bates e indexadas em planilhas.
- Humanos e máquinas classificam texto.
Software de apontar e clicar que qualquer pessoa pode dominar.
Os humanos são bons em algumas coisas e os computadores são bons em outras. Um vaivém consistente entre humanos e máquinas aumenta a capacidade de aprendizagem de ambos. Nosso software de análise de texto e métodos de ciência de dados se originaram em uma década de pesquisas financiadas pela National Science Foundation sobre as medições que aceleram o aprendizado de máquina. A classificação de textos é um problema antigo e difícil, de acordo com nada menos que Platão. Nosso método único e comprovado de adjudicação cria conjuntos de treinamento padrão ouro para aprendizado de máquina, classificando anotadores humanos ao longo do tempo. Uma abordagem CoderRank patenteada é crítica para garantir resultados precisos e confiáveis quando o trabalho de humanos ou máquinas é finalmente avaliado.
- Ferramentas de eDiscovery que funcionam.
Técnicas avançadas de pesquisa e amostragem.
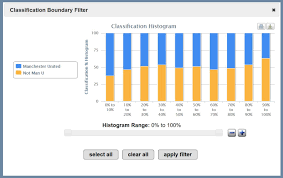
A desduplicação e o clustering automatizado de quase duplicatas fornecem aos usuários uma noção de alto nível do cenário de dados. Com os dados do Twitter, esses agrupamentos são um roteiro para a pegada digital de Tweets virais . Com os dados de comentários públicos, esses agrupamentos são cartas padrão e formulários modificados. Em pesquisas em grande escala, duplicatas e quase duplicatas são frequentemente realizadas, mas opiniões expressas de forma independente entre clientes ou funcionários. Nossos histogramas de classificador de máquina interativa permitem que as equipes de ciência de dados identifiquem os itens em uma coleção que agregam mais valor quando codificados por humanos . Essas ferramentas analíticas de texto permitem uma amostragem intencional que acelera ainda mais o processo de treinamento de classificadores de máquinas.
Produtos Relacionados



Obrigado! Logo entraremos em contato!
Baixe o Guia Software.com.br 2024



































